정보처리기사 - 1~3과목 이론 정리
자료사전(Data Dictionary)
= : 자료의 정의(~로 구성되어 있다)
+ : 자료의 연결(그리고)
() : 자료의 생략(생략 가능한 자료)
[] : 자료의 선택(또는) ex) [ A | B | C ]
{} : 자료의 반복
* * : 자료의 설명(주석)
소프트웨어 설계
상위 설계 : 아키텍처 설계, 데이터 설계, 시스템 분할, 인터페이스 정의, 사용자 인터페이스 설계(UI 설계)
하위 설계 : 모듈 설계, 인터페이스 작성
코드 설계
1. 연상 코드: 항목의 명칭이나 약호와 관계 있는 숫자, 문자, 기호를 이용하여 코드를 부여하는 방법
2. 블록 코드: 대상 항목에서 공통적인 것을 블록으로 구분하고 블록 내에 일련 번호를 부여하는 방법
3. 순차 코드: 일정 기준에 따라 최초의 자료부터 일련번호를 부여하는 방법
4. 표의 숫자 코드: 길이 넓이 부피 등 항목의 성질의 물리적인 수치를 그대로 코드에 적용시키는 방법
CASE(Computer-Aided Software Engineering)도구
CASE의 원천 기술
구조적 기법, 프로토타이핑 기술, 자동프로그래밍 기술, 정보 저장소 기술, 분산 처리 기술
소프트웨어 공학의 자동화를 의미, 소프트웨어 공학작업을 자동화한 소프트웨어 패키지 CASE도구
CASE도구들은 소프트웨어 관리자들과 실무자들이 소프트웨어 프로세스와 관련된 활동을 지원한다. 즉, 프로젝트 관리 활동을 자동화하고, 결과물을 관리하며, 엔지니어들의 분석, 설계 및 코딩과 테스트작업을 도움
주요기능: 다양한 소프트웨어 개발 모형 지원, 그래픽 지원, 소프트웨어 생명주기의 전단계 연결
CASE는 1980년대에 소개되었으며, 1990년대부터 자주 사용
CASE는 객체지향 시스템 뿐만 아니라 구조 시스템등 모든분야에 적용됨
객체지향 프로그램
클래스
- 객체지향 프로그램에서 데이터를 추상화하는 단위이다.
- 공통된 속성과 연산(행위)를 갖는 객체의 집합.
메소드
- 객체의 메소드는 다른 객체로부터 메시지를 받았을 때 정해진 기능을 수행한다.
상속성
- 이미 정의된 상위 클래스(부모 클래스)의 모든 속성과 연산을 하위 클래스(자식 클래스)가 물려받는 것이다.
소프트웨어의 '재사용'을 높이는 중요한 개념.
메시지
- 객체들 간의 상호작용을 하는 데 사용되는 수단으로, 객체에게 어떤 행위를 하도록 지시하는 명령 또는 요구사항이다.
XP(eXtreme Programming)의 5가지 가치
용기(Courage) : 고객의 요구사항 변화에 능동적인 대처
단순성(Simplicity) : 부가적 기능, 사용되지 않는 구조와 알고리즘 배제
커뮤니케이션(Communication) : 개발자, 관리자, 고객 간의 원활한 의사소통
피드백(Feedback) : 지속적인 테스트와 반복적 결함 수정, 빠른 피드백
존중(Respect) : 모든 프로젝트 관리자는 팀원의 기여를 존중
인터페이스 구현 검증 도구
xUnit : Java, C++ 등 다양한 언어 지원하는 단위 테스트 프레임워크
STAF : 서비스 호출 및 컴포넌트 재사용 등 환경 지원하는 테스트 프레임워크
FitNesse : 웹 기반 테스트케이스 설계, 실행, 결과 확인 등을 지원하는 테스트 프레임워크
NTAF : FitNesse의 장점인 협업 기능과 STAF의 장점인 재사용 및 확장성을 통합한 네이버의 테스트 자동화 프레임워크이다.
Selenium : 다양한 브라우저 및 개발 언어 지원하는 웹 애플리케이션 테스트 프레임워크
Watir : Ruby를 사용하는 애플리케이션 테스트 프레임워크
Ruby : 인터프리터 방식의 객체지향 스크립트 언어
소스코드 품질분석 도구
정적 분석 도구
pmd :소스 코드에 대한 미사용 변수 최적화안된 코드 등 결함을 유발할 수 있는 코드 검사
cppcheck : C/C++ 코드에 대한 메모리 누수 오버플로우 등 분석
SonarQube : 중복 코드 복잡도 코딩 설계 등을 분석하는 소스 분석 통합 플랫폼
checkstyle : 자바 코드에 대해 소스코드 표준을 따르고 있는지 검사한다.
ccm : 다양한 언어의 코드 복잡도를 분석한다.
cobertura : 자바 언어의 소스코드 복잡도 분석 및 테스트 커버리지 측정
동적 분석 도구
Avalanche : Valgrind 프레임워크 및 STP기반 / 프로그램 결함 및 취약점 분석
valgrind : 프로그램 내에 존재하는 메모리 및 쓰레드 결함 분석
트렌잭션특성
Atomicity(원자성)
1. 트랜잭션의 연산은 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야 한다.
2. 트랜잭션 내의 모든 명령은 반드시 완벽히 수행되어야 하며, 모두가 완벽히 수행되지 않고 어느하나라도 오류가 발생하면 트랜잭션 전부가 취소되어야 한다.
Consistency(일관성)
1. 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
2. 시스템이 가지고 있는 고정요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다.
Isolation(독립성,격리성)
1. 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행중에 다른 트랜잭션의 연산이 끼어들 수 없다.
2. 수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다.
Durablility(영속성,지속성)
1. 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
애플리케이션테스트
단위 테스트(Unit Test)
: 하나의 "모듈"을 기준으로 독립적으로 진행되는 가장 작은 단위의 테스트
내부에 존재하는 논리적인 오류를 검출, 기능이 제대로 수행되는지 점검
통합 테스트(Integration Test):
모듈을 통합하는 과정에서 "모듈 간의" 호환성을 확인하기 위해 수행되는 테스트
시스템 테스트(System Test):
"완전한 시스템"에 대해 수행하는 테스트. 기능적, 비기능적 요구사항을 만족하는지 확인
인수(Acceptance Test):
실제 환경에서 "사용자"가 참여하는 테스트. 요구 분석 명세서에 나타난 사항을 모두 충족하는지, 시스템이 예상대로 동작하는지 사용자의 관점에서 확인
EAI(Enterprise Application Integration)의 구축 유형
Point - to - Point : 가장 기본적인 애플리케이션 통합 방식 1:1로 연결
Hub & Spoke : 단일 접점인 허브 시스템을 통해 데이터 전송하는 중앙 집중형 방식
Message Bus : 애플리케이션 사이에 미들웨어를 두어 처리하는 방식
Hybrid : Hub & Spoke 와 Message Bus 혼합 방식
빌드 자동화 도구
- 빌드를 포함하여 테스트 및 배포를 자동화하는 도구
- Ant, Make, Maven, Gradle, Jenkins 등이 있음
Jenkins
- JAVA 기반의 오픈소스 형태
- 서블릿 컨테이너에서 실행되는 서버 기반 도구
- 친숙한 Web GUI 제공
- 분산 빌드나 테스트 가능
Gradle
- Groovy를 기반으로 한 오픈 소스 형태
- 안드로이드 앱 개발 환경에서 사용
- 행할 처리 명령들을 모아 태스크(Task)로 만든 후 태스크 단위로 실행
반정규화 유형 외우는법
(진) 행테이블추가
(집) 계테이블추가
(보수) 특정 부분만 포함하는 테이블 추가함
ISO/IEC 9126 제품특성
기능성 : 적합성 정확성 상호운용성 보안성 준수성
신뢰성 : 성숙성 결함허용성 복구성
사용성 : 이해성 학습성 운용성 준수성
효율성 : 시간반응성 자원효율성 준수성
유지보수성 : 분석성 변경성 안정성 시험성 준수성
이식성 : 적응성 설치성 공존성 대체성 준수성
데이터베이스의 논리적 설계(logical design) 단계
-현실 세계에서 발생하는 자료를 컴퓨터가 이해하고 처리할 수 있는 물리적 저장장치에 저장할 수 있도록 변환하기 위해 특정 DBMS가 지원하는 논리적 자료 구조로 변환시키는 과정
-개념 세계의 데이터를 필드로 기술된 데이터 타입과 이 데이터 타입들 간의 관계로 표현되는 논리적 구조의 데이터로 모델화
-개념 스키마를 평가 및 정제하고 DBMS에 따라 서로 다른 논리적 스키마를 설계하는 단계(종속적인 논리 스키마)
-트랜잭션의 인터페이스 설계
-관계형 데이터베이스라면 테이블 설계
-특정목표 DBMS에 따른 스키마설계
-스키마의 평가 및 정제
분산 데이터베이스 목표
-위치투명성(Location Trasparency) 데이터 베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적인 명칭만으로 엑세스할 수 있음
-중복투명성(Replication Transparency) 데이터가 여러 곳에 중복되어 있더라도 사용자는 마치 하나의 데이터만 존재하는 것 처럼 사용 가능, 시스템은 자동으로 여러 자료에 대한 작업 수행
-병행투명성(Concurrency Transparency) 다수의 트랜잭션이 동시에 실현되더라도 그 결과는 영향을 받지 않음
-장애투명성(Failure Transparency) 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 트랜잭션을 정확히 처리함.
트랜잭션의 특성
Durability 영속성 : 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
Consistency 일관성 : 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
Atomicity 원자성 : 트랜잭션 연산은 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야 한다.
Isolation 격리성 : 트랜잭션 실행 중 생성하는 연산의 중간 결과를 다른 트랜잭션이 접근 불가하다.
DDL
PRIMARY KEY : 기본키 정의 / FOREIGN KEY : 외래키 정의
UNIQUE : 지정 속성은 중복값 가질 수 없음 / NO ACTION : 변화가 있어도 조취를 취하지 않음
CASCADE : 참조 테이블 튜플 삭제 시 관련 튜플 모두 삭제 및 속성 변경 시 속성값 모두 변경
RESTRICTED : 타 개체가 제거할 요소를 참조중이면 제거를 취소
SET NULL : 참조 테이블 변화 시 기본 테이블 관련 속성값 Null로 변경
SET DEFAULT : 참조 테이블 변화 시 기본테이블의 관련 튜플 속성값을 기본값으로 변경
CONSTRAINT : 제약 조건 이름 지정 / CHECK 속성값에 대한 제약 조건 정의
DML
INSERT INTO ~ VALUES : 튜플 삽입 / DELETE FROM~ WHERE : 튜플 삭제
UPDATE ~ SET ~ WHERE : 튜플 내용 변경 / SELECT~FROM~WHERE : 튜플 검색
DISTINCT : 중복 튜플 발견 시 그 중 첫번째 하나만 검색 / DISTINCTROW : 중복 튜플 제거 및 하나만 검색 (튜플 전체를 대상으로 검색)
PREDICATE : 검색할 튜플 수 제한 / AS 속성명 정의
ORDER BY : 특정 속성 기준으로 정렬 후 검색할 때
ASC : 오름차순 / DESC : 내림차순 / 생략 시 오름차순
GROUP BY : 특정 속성 기준 그룹화하여 검색할 때 사용 having절과 같이 사용되어야함
미들웨어 솔루션의 유형
1. WAS(웹 애플리케이션 서버)
- 사용자의 요구에 따라 변하는 동적인 콘텐츠를 처리함
- 웹 환경을 구현하기 위한 미들웨어
(제외 2. Web Server
- 클라이언트로부터 직접 요청을 받아 처리, 저용량의 정적 파일들을 제공하는 소프트웨어)
3. RPC(Remot Procedure Call)
- 응용 프로그램이 프로시저를 사용하여 원격 프로시저를 마치 로컬 프로시저처럼 호출하는 미들웨어
4. ORB(Object Request Broker)
- 객체 지향 미들웨어로 코바(CORBA) 표준 스펙을 구현함
- 최근에는 TP-Monitor의 장점인 트랜잭션 처리와 모니터링 등을 추가로 구현한 제품도 있음
시퀀스(Sequence) 다이어그램 - 액, 객, 생, 메, 실
: 메시지(함수호출)를 주고받으면서 시간의 흐름에 따라 상호작용하는 과정들(그림으로 표현)
액터(Actor) : 시스템으로부터 서비스를 요청하는 외부요소로, 사람이나 외부 시스템 의미
객체(object) : 메시지를 주고받는 주체
생명선(Lifeline) : 객체가 메모리에 존재하는 기간으로, 객체 아래쪽에 점선을 그어 표현
메시지(Message) : 객체가 상호 작용을 위해 주고받는 메시지
실행 상자(Active Box) : 객체가 메시지를 주고받으며 구동되고 있음을 표현
객체지향 설계원칙
1. 단일 책임 원칙(SRP, Single Responsibility Principle)
객체는 단 하나의 책임만 가져야 한다.
2. 개방-폐쇄의 원칙(OCP, Open Closed Principle)
기존의 코드를 변경하지 않으면서 기능을 추가할 수 있도록 설계가 되어야 한다.
3. 리스코프 치환 원칙(LSP, Liskov Substitution Principle)
일반화 관계에 대한 이야기며, 자식 클래스는 최소한 자신의 부모 클래스에서 가능한 행위는 수행할 수 있어야 한다.
4. 인터페이스 분리 원칙(ISP, Interface Segregation Principle)
인터페이스를 클라이언트에 특화되도록 분리시키라는 설계 원칙이다.
5. 의존 역전 원칙(DIP, Dependency Inversion Principle)
의존 관계를 맺을 때 변화하기 쉬운 것 또는 자주 변화하는 것보다는 변화하기 어려운 것, 거의 변화가 없는 것에 의존하라는 것.
패키지 소프트웨어의 일반적인 제품 품질 요구사항 및 테스트를 위한 국제 표준
ISO/IEC 12119 패키지 소프트웨어 제품테스트 국제 표준
현재 ISO/IEC 12119 이 대체되어 ISO/ISE 25010이 국제표준
페이지 교체 알고리즘의 종류
OPT - Optimal : 앞으로 가장 오랫동안 사용되지 않을 페이지 교체
FIFO - First In First Out
LRU - Least Recently Used : 가장 오랫동안 사용되지 않은 페이지 교체
LFU - Least Frequently Used : 참조 횟수가 가장 작은 페이지 교체
MFU - Most Frequently used : 참조 횟수가 가장 많은 페이지 교체
NUR - Not Used Recently : 최근에 사용하지 않은 페이지 교체
제어흐름 그래프가 다음과 같을 때 McCabe의 cyclomatic 수
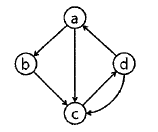
V(G) = Edge - Node + 2
Edge = 6 (화살표)
Node = 4 (동그라미)
V(G) = 6 - 4 + 2 = 4
< 파티션 유형 > -범해조
- 범위 분할(Range Partitioning) : 지정한 열의 값을 기준으로 분할
- 해시 분할(Hash Partitioning) : 해시 함수를 적용한 결과 값에 따라 데이터 분할
- 조합 분할(Composite Partitioning) : 범위 분할 후 해시 함수를 적용하여 다시 분할
분산 데이터베이스의 목표
1. Location Transparency (위치 투명성)
: 데이터베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적 명칭만으로 액세스할 수 있음
2. Replication Transparency (중복 투명성; 복제 투명성)
: 동일 데이터가 여러 곳에 중복되어 있더라도 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용하고, 시스템은 자동으로 여러 자료에 대한 작업을 수행
3. Failure Transparency (장애 투명성)
: 장애가 발생해도 트랜잭션을 정확하게 처리하고 데이터 무결성을 보장함
4. Concurrency Transparency (병행 투명성)
: 다수의 트랜잭션들이 동시에 실현되더라도 그 트랜잭션의 결과는 영향을 받지 않음
5. Division Transparency (분할 투명성)
: 하나의 논리적 릴레이션이 여러 단편으로 분할되어 각 단편의 사본이 여러 시스템에 저장되어 있음을 인식할 필요가 없음
알고리즘 설계 기법
1.Divide and Conquer(분할 정복 알고리즘) : 그대로 해결할 수 없는 문제를 작은 문제로 분할하여 문제를 해결하는 알고리즘
2. Greedy(탐욕 알고리즘) : 현재 시점에서 가장 최적의 방법을 선택하는 알고리즘
4. Backtracking : 모든 조합을 시도하여 문제의 답을 찾는 알고리즘
디지털 저작권 관리(DRM) 기술 요소
- 암호화(Encryption) : 콘텐츠 및 라이선스를 암호화하고 전자 서명을 할 수 있는 기술
- 키 관리(Key Management) : 콘텐츠를 암호화한 키에 대한 저장 및 분배 기술
- 암호화 파일 생성(Packager) : 콘텐트를 암호화된 콘텐츠로 생성하기 위한 기술
- 식별 기술(Identification) : 콘텐츠에 대한 식별 체계 표현 기술
- 저작권 표현(Right Expression) : 라이선스의 내용 표현 기술
- 정책 관리(Policy Management) : 라이선스 발급 및 사용에 대한 정책 표현 및 관리 기술
- 크랙 방지(Tamper Resistance) : 크랙에 의한 콘텐츠 사용 방지 기술
- 인증(Authentication) : 라이선스 발급 및 사용의 기준이 되는 사용자 인증 기술
CRUD 분석
생성(Create), 읽기(Read), 갱신(Update), 삭제(Delete)의 영어 앞글자를 모아 만든 용어이며, CRUD 분석은 데이터베이스 테이블에 변화를 주는 트랜잭션의 CRUD 연산에 대해 CRUD 매트릭스를 작성하여 분석하는 것이다.
·데이터 웨어하우스 (Data Warehouse):
급증하는 다량의 데이터를 효과적으로 분석하여 정보화하고 이를
여러 계층의 사용자들이 효율적으로 사용할 수 있도록 한 데이터베이스.
roll-up, slicing & dicing, drill-up & down, pivot, drill-through 등
·OLAP (Online Analytical Processing)
다차원으로 이루어진 데이터로부터 통계적인 요약 정보를 분석하여 의사 결정에 활용하는 방식
정렬방식
*퀵 정렬: 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬하는 방식
*삽입정렬: 가장 간단한 정렬 방식, 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬
*쉘 정렬: 삽입정렬 확장 개념, 입력파일을 매개변수값으로 서브파일 구성하고 각 서브파일을 삽입정렬 방식으로 순서 배열하는 과정을 반복하는 정렬
*선택정렬: n개의 레코드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 n-1개 중에서 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하는 정렬
*버블정렬: 주어진 파일에서 인접한 두 개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식
*힙 정렬: 전이진 트리를 이용한 정렬 방식
*2-Way 합병 정렬: 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식
비밀키(대칭키)는 N(N-1)/2 이고
공개키(비대칭키) 2N개 입니다
데이터베이스 설계
개념적 설계: 사용자의 요구사항 분석 후, 데이터베이스에 대한 추상적인 형태를 설계
- 개념적 모델을 이용한 개념적 스키마 생성(데이터베이스에 대한 추상적인 설계도, 개체 관계 다이어그램)
논리적 설계: 논리적 모델을 이용하여 논리적 스키마 생성
- ERD를 이용하여 데이터베이스 스키마를 설계, 테이블 구조도, 개념적 설계 단계에서 생성된 ERD를 바탕으로 생성되는 테이블들의 집합
물리적 설계: 특정 DBMS가 제공하는 물리적 구조에 따라 테이블 저장 구조 설계
- 필드의 데이터 타입, 인덱스, 테이블 저장 방법 등을 정의
병행제어 기법의 종류
로타최다
로킹 기법
타임 스탬프 기법
최적 병행 수행 기법 (검증 기법, 확인 기법, 낙관적 기법)
다중 버전 기법